Data once belonged to machines
Early data analysis did not begin on a personal screen. It lived in punch cards, mainframes, batch jobs, and rooms built for specialists.
Before data became visible, it had to be prepared for the machine.

Early data analysis did not begin on a personal screen. It lived in punch cards, mainframes, batch jobs, and rooms built for specialists.
Before data became visible, it had to be prepared for the machine.
The spreadsheet changed that relationship. Data moved onto the personal screen, into cells people could see, edit, copy, and question.
For the first time, working with data felt close to working with paper.

Statistical software, programming languages, and databases made analysis rigorous, deep, and repeatable.
But these tools often assume one thing: the data is already prepared.
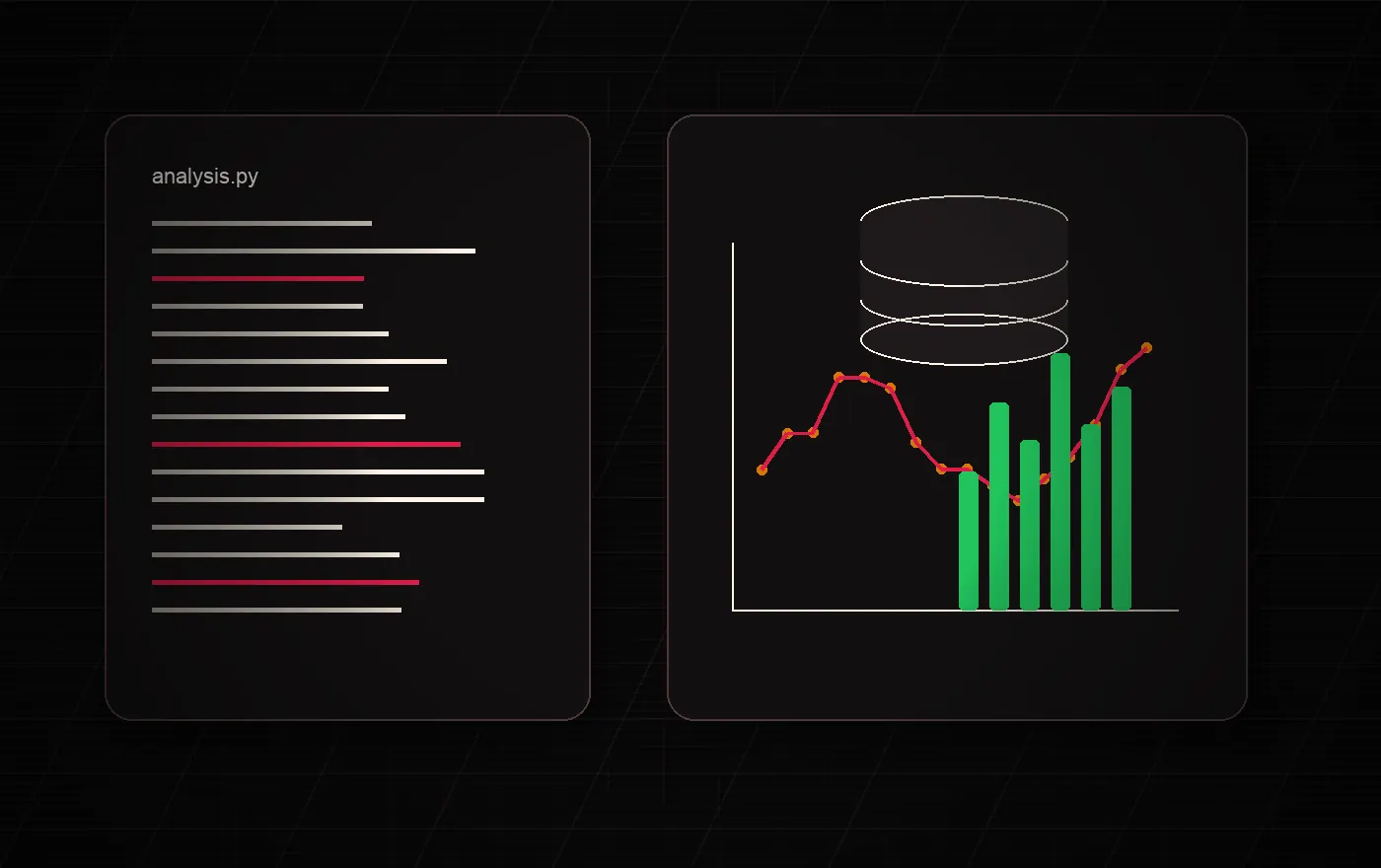
Real-world data rarely arrives in an ideal state. Fields change, formats drift, definitions disagree, sources split apart, and judgment stays hidden in experience.
Tools became more powerful, but the step before those tools remained difficult.
IMD is built for this step. It is an AI-native data workspace for turning messy real-world data into clear, trustworthy, reusable, and deliverable outputs.
Not to decorate the end of analysis, but to make the hardest part before analysis easier to handle.
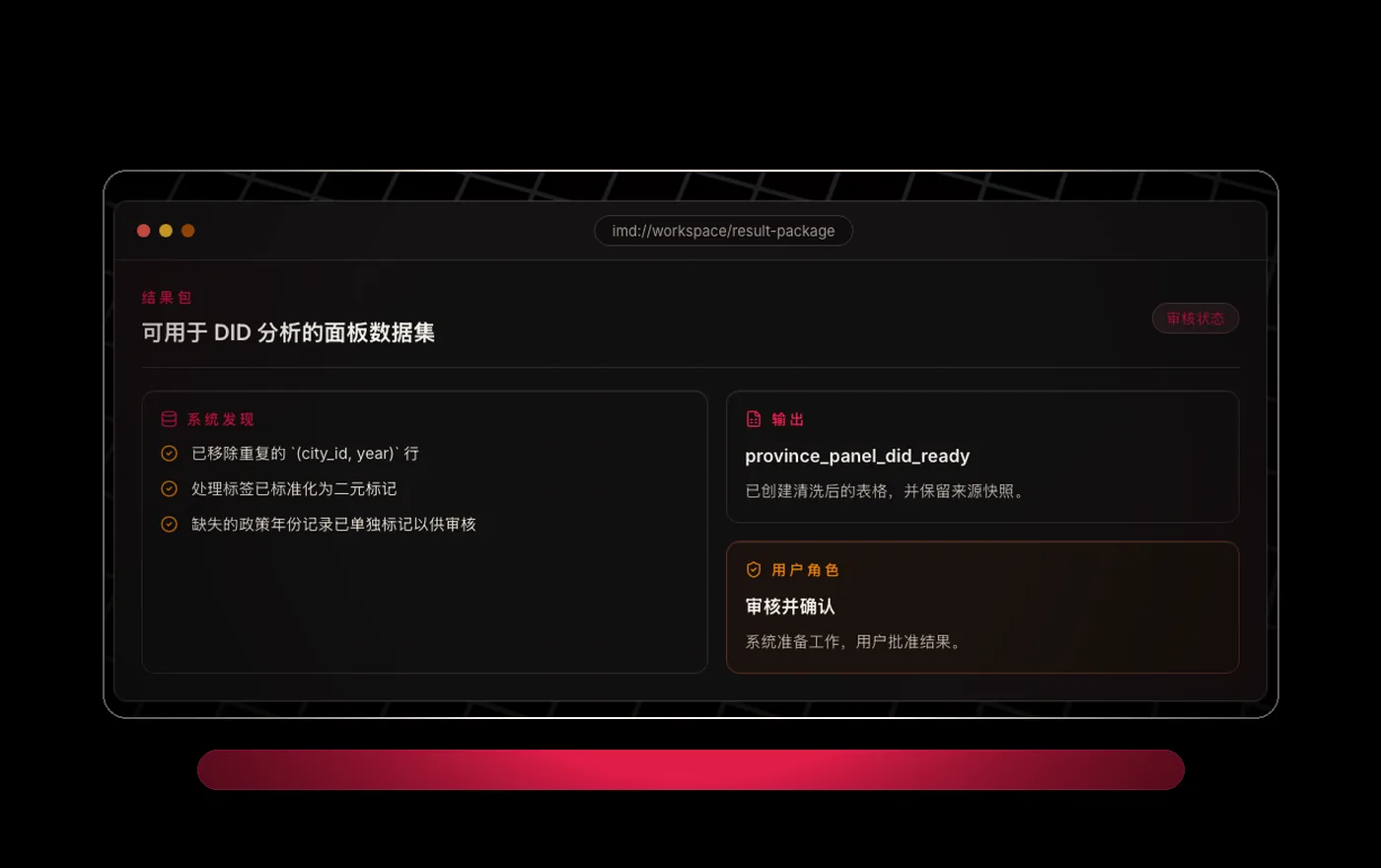
让天下没有难处理的数据。