一张还不能被分析的表
如果你正在读这篇文章,你可能也熟悉这样的时刻:项目已经开始,问题已经明确,但真正摆在面前的,是一张还不能被分析的表。
字段不一致,格式不统一,来源分散,口径含混。结论看似不远,最先出现的却总是整理、判断和反复确认。

如果你正在读这篇文章,你可能也熟悉这样的时刻:项目已经开始,问题已经明确,但真正摆在面前的,是一张还不能被分析的表。
字段不一致,格式不统一,来源分散,口径含混。结论看似不远,最先出现的却总是整理、判断和反复确认。
分析者本应把时间用在理解问题、建立模型和解释结果上,却常常先被迫成为数据的整理者。
这一步很少被看见,却决定了后面的分析能否顺畅推进,决定了结论是否足够可靠,也决定了一个项目会被卡住多久。
为了理解这一步为什么反复出现,也为了说明 IMD 为什么从这里开始,我们需要回到数据工具的历史。

早期的数据分析并不是从个人屏幕开始的。它存在于打孔卡、大型机、批处理任务,以及为专业人员而设的房间里。
在数据变得可见之前,它必须先被整理成机器能够理解的形态。

电子表格改变了这种关系。数据来到个人屏幕上,进入人们可以看见、编辑、复制和追问的单元格里。
第一次,处理数据变得像处理纸面一样直接。

统计软件、编程语言和数据库工具,让数据分析变得严谨、深刻、可重复。
但这些工具往往默认一件事:数据已经准备好了。
现实中的数据很少以理想状态出现。字段会变化,格式会混乱,口径会不一致,来源会分散,判断也常常藏在人的经验里。
工具越来越强,但进入工具之前的那一步,依然困难。
AI 让很多人第一次感到,数据分析可以变得更简单。问题可以被解释,代码可以被生成,报告也可以更快出现。
但当底层数据仍然混乱时,AI 并不会自动给出可靠结论,也无法稳定执行那些需要上下文、约束和判断的数据整理动作。

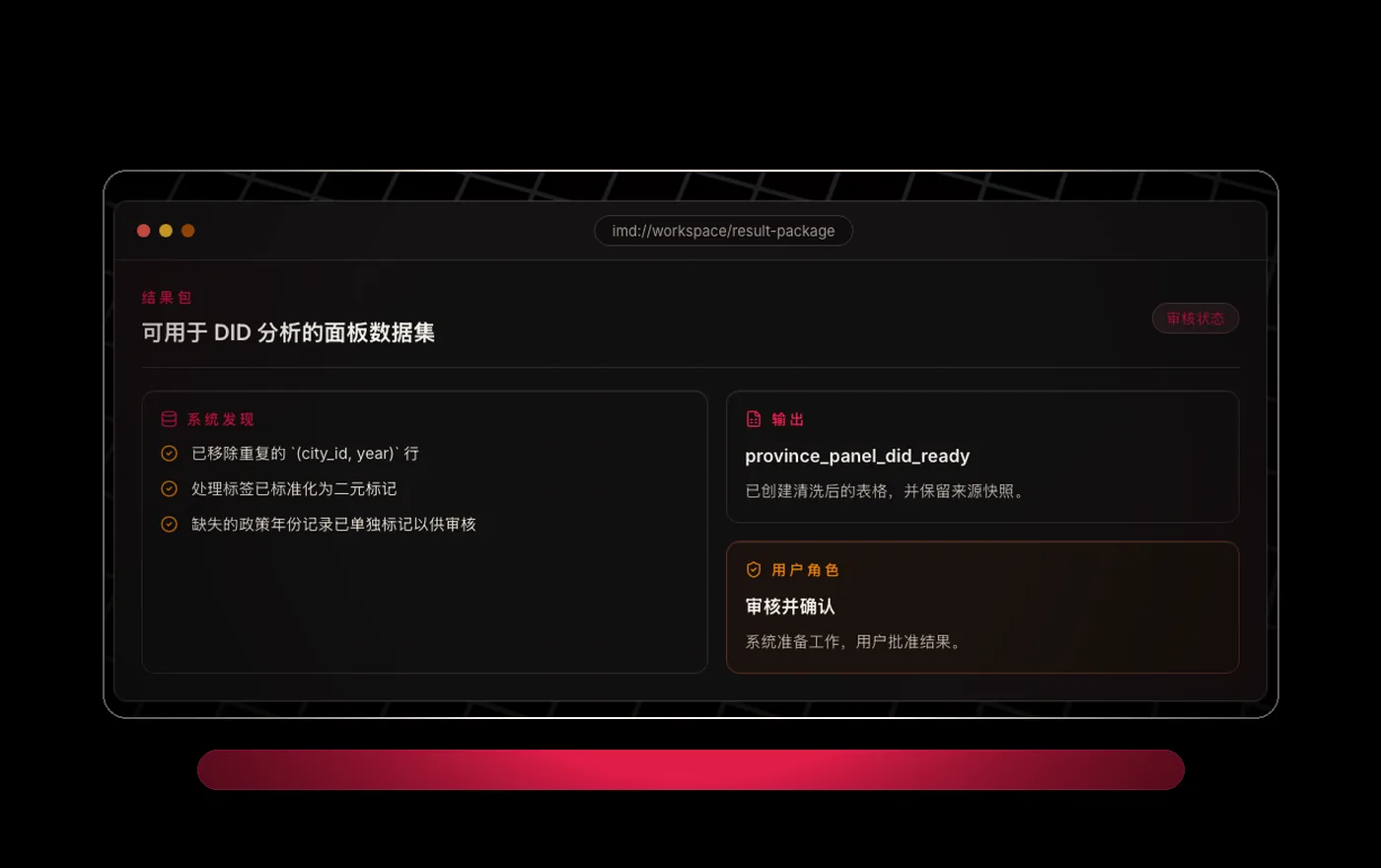
IMD 为这一步而生。它是一个 AI Native 数据工作台,用来把混乱的真实数据,转化为清晰、可信、可复用、可交付的结果。
不是在分析之后锦上添花,而是在分析开始之前,把最难处理的部分变简单。
我们相信,下一代数据工具不只是更快地执行命令,而是重新分配人与机器的位置。
机器负责整理、转换和复用那些可以被定义的工作;分析者回到判断、审阅和理解世界本身。

To make every dataset easy to work with.