데이터는 한때 기계의 것이었습니다
초기의 데이터 분석은 개인 화면에서 시작되지 않았습니다. 펀치카드, 메인프레임, 배치 작업, 그리고 전문가를 위한 공간 안에 있었습니다.
데이터가 보이는 것이 되기 전에, 먼저 기계가 이해할 수 있는 형태로 정리되어야 했습니다.

초기의 데이터 분석은 개인 화면에서 시작되지 않았습니다. 펀치카드, 메인프레임, 배치 작업, 그리고 전문가를 위한 공간 안에 있었습니다.
데이터가 보이는 것이 되기 전에, 먼저 기계가 이해할 수 있는 형태로 정리되어야 했습니다.
스프레드시트는 그 관계를 바꾸었습니다. 데이터는 개인 화면으로 옮겨졌고, 사람들이 보고, 편집하고, 복사하고, 질문할 수 있는 셀 안에 들어왔습니다.
처음으로 데이터를 다루는 일이 종이를 다루는 일처럼 직접적으로 느껴졌습니다.

통계 소프트웨어, 프로그래밍 언어, 데이터베이스는 분석을 엄밀하고 깊고 반복 가능한 일로 만들었습니다.
하지만 이런 도구들은 대개 한 가지를 전제합니다. 데이터가 이미 준비되어 있다는 것입니다.
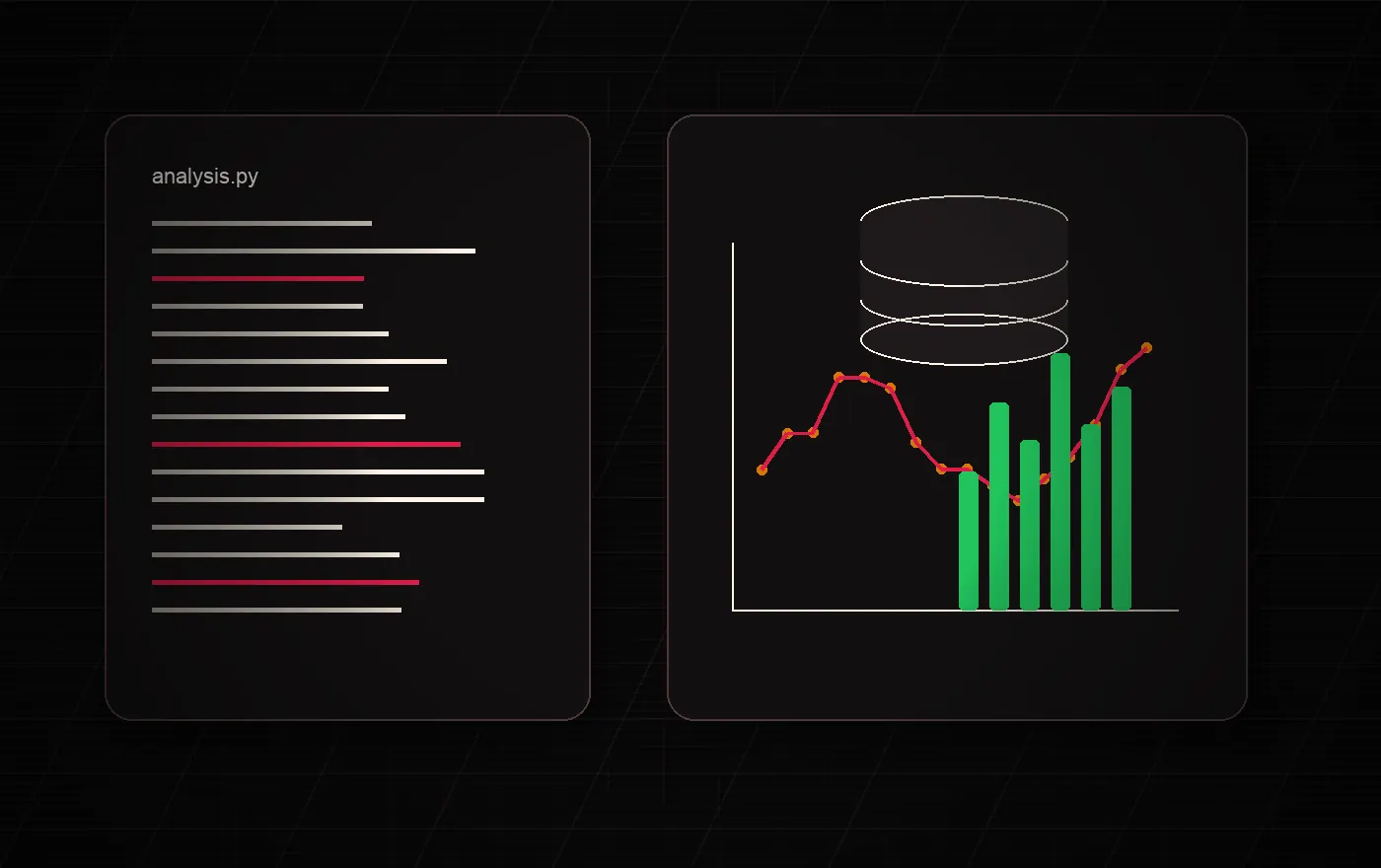
현실의 데이터는 이상적인 상태로 도착하는 일이 드뭅니다. 필드는 바뀌고, 형식은 흔들리고, 정의는 어긋나며, 출처는 흩어지고, 판단은 사람의 경험 속에 숨어 있습니다.
도구는 점점 강력해졌지만, 그 도구에 들어가기 전의 한 단계는 여전히 어려웠습니다.
IMD는 이 단계를 위해 만들어졌습니다. 복잡한 현실 데이터를 명확하고, 신뢰할 수 있고, 재사용 가능하며, 전달 가능한 결과물로 바꾸는 AI Native 데이터 워크스페이스입니다.
분석 이후를 장식하기 위해서가 아니라, 분석이 시작되기 전 가장 다루기 어려운 부분을 쉽게 만들기 위해 존재합니다.
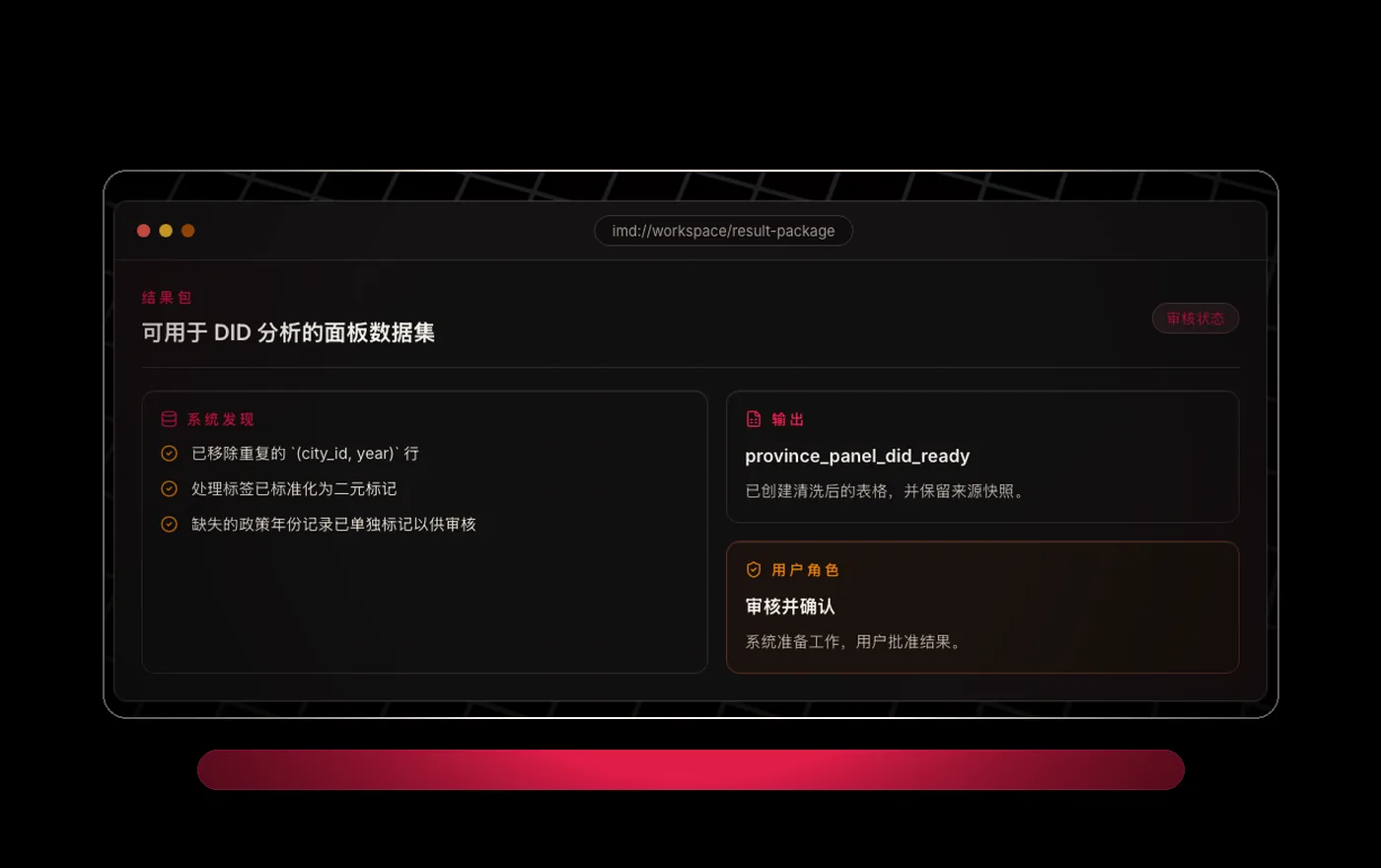
To make every dataset easy to work with.